Using Custom Search: CSS Selectors
Custom Search is an option in WebSite Auditor that lets you look for specific pieces of content (text, HTML code substrings, scripts, etc.) while crawling a site.
It can be used to search for a simple keyword mention, as well as for complex pieces like HTML code substrings, scripts, Google Tag Manager or Google Analytics codes, structured data markup and heading tags, etc.
If you need to locate substrings in the code of an html document, WebSite Auditor has three search modes:
- Contains – list all pages of the website that contain the substring (case-insensitive)
- Does not contain – list all pages of the website that do not contain the substring (case-insensitive)
- CSS Selectors – list all pages of the website that include the code matching the selector
Contains / Doesn’t Contain functionality is obvious. Just put a search string in the field and press the Search button to get the results.
Mastering CSS selectors requires more time and further reading.
CSS Selectors
In cascading style sheets (CSS), selectors are patterns used to select the element(s) you want to style. You may use CSS selectors to locate elements in a document written in a markup language (e.g. HTML) as well.
Selectors may apply to:
- all elements of a specific type, e.g. the second-level headers h2
- elements specified by an attribute, in particular:
- id: an identifier unique within the document
- class: an identifier that can annotate multiple elements in a document
- elements depending on how they are placed relative to others in the document tree.
In order to get most of the CSS selectors functionality, you must understand the basic concepts of the html document structure.
HTML document Structure
Tag – begins with less-than ‘<’ followed by a string (e.g. ‘div’), an optional space, an optional number of attributes, and ends with more-than ‘>’ sign. There are start <html>and end </html>tags.
For example: <html></html>, <div></div>, <p></p>.
Attribute – attributes provide additional information about a tag (or element). Attributes are always specified in the opening tag. Attributes usually come in name/value pairs like: name="value".
For example, href=”http://homepage.com”.
Class – is a specific type of attribute. The class attribute is mostly used to point to a class in a style sheet. However, it can also be used by a JavaScript (via the HTML DOM – ссылка) to make changes to HTML elements with a specified class.
For example, class="comments".
ID – is a specific type of attribute. The id attribute is mostly used to point to a style in a style sheet, and by JavaScript (via the HTML DOM) to manipulate the element with the specific id. The id attribute specifies a unique id for an HTML element (the value must be unique within the HTML document).
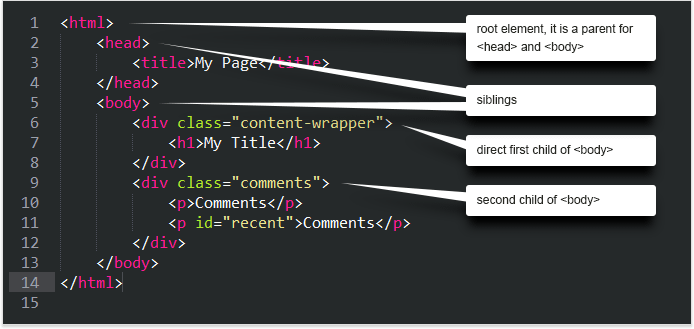
Elements may be described using their position relative to other elements. In the example code below, <html> is a root element, it is a parent for <head> and <body>. <head> and <body> are siblings. <div class="content wrapper"> is a direct first child of <body>. <div class="comments"> is the second child.
CSS Selectors Basic Syntax
This is the list of basic CSS selector expressions that you may use in WebSite Auditor.
| Pattern | Matches | Example |
| * | any element | * |
| tag | elements with the given tag name | div |
| ns|E | elements of type E in the namespace ns | fb|name finds <fb:name> elements |
| .class | elements with the attribute ID of "id" | div.left, .result |
| [attr] | elements with an attribute named "attr" (with any value) | a[href], [title] |
| [∧attrPrefix] | elements with an attribute name starting with "attrPrefix". Use to find elements with HTML5 datasets | [∧data-], div[∧data-] |
| [attr=val] | elements with an attribute named "attr", and value equal to "val" | img[wdth=500], a[rel=nofollow] |
| [attr="val"] | elements with an attribute named "attr", and value equal to "val" | span[hello="Cleveland"][goodbye="Columbus"], a[rel="nofollow"] |
| [attr∧=valPrefix] | elements with an attribute named "attr", and value starting with "valPrefix" | a[href∧=http:] |
| [attr$=valSuffix] | elements with an attribute named "attr", and value ending with "valSuffix" | img[src$=.png] |
| [attr*=valContaining] | elements with an attribute named "attr", and value containing "valContaining" | a[href*=/search/] |
| [attr~=regex] | elements with an attribute named "attr", and value matching the regular expression | img[src~=(?i)\\.(png|jpe?g)] |
The above may be combined in any order.
| For example, div.header[title] query will return all the pages that include <div> tags with class ‘header’ and attribute ‘title’. |
The selectors may be combined as well
| Pattern | Matches | Example |
| E F | an F element descended from an E element | div a, .logo h1 |
| E > F | an F direct child of E | ol > li |
| E + F | an F element immediately preceded by sibling E | li + li, div.head + div |
| E ~ F | an F element preceded by sibling E | h1 ~ p |
| E, F, G | all matching elements E, F, or G | a [href], div, h3 |
For more information about the syntax visit this page.
Some examples for SEO needs
|
Find all pages... |
String |
| with Google Tag Manager tracking script (insert the container id instead of XXX-XXXXXX) | noscript:has(iframe[src$=XXX-XXXXXX]) |
| with h1 tag | h1 |
| with inconsistent usage of h1 and h2 tags (any pages where h1 tag is precedded by h2 sibling) | h2 ~ h1 |
| with the certain canonical tag (insert the real URL instead of http://domain.com/page.html) | link[rel=canonical][href^=http://domain.com/page.html] |
| with images that have a certain alt attribute | img[alt=green-grass] |
| that link back to a certain page | a[href*=page.html] |
| that link back to https pages | a[href^=https] |
| containing word "SEO" in title | title:contains(seo) |
| with open graph protocol markup | meta[name^=og:] |
| with Twitter cards markup | meta[name^=twitter:] |
| with iframes | iframe |
| containing e-mail links | a[href^=mailto:] |
| class="green-cell" | link[hreflang] |
| containing word "SEO" in meta words | meta[name="keywords"][content*=seo] |
Comments
0 comments
Please sign in to leave a comment.